We introduce Replay, a collection of multi-view, multi-modal videos of humans interacting socially. Each scene is filmed in high production quality, from different viewpoints with several static cameras, as well as wearable action cameras, and recorded with a large array of microphones at different positions in the room. Overall, the dataset contains over 3000 minutes of footage and over 5 million timestamped high-resolution frames annotated with camera poses and partially with foreground masks. The Replay dataset has many potential applications, such as novel-view synthesis, 3D reconstruction, novel-view acoustic synthesis, human body and face analysis, and training generative models. We provide a benchmark for training and evaluating novel-view synthesis, with two scenarios of different difficulty. Finally, we evaluate several baseline state-of-the-art methods on the new benchmark.
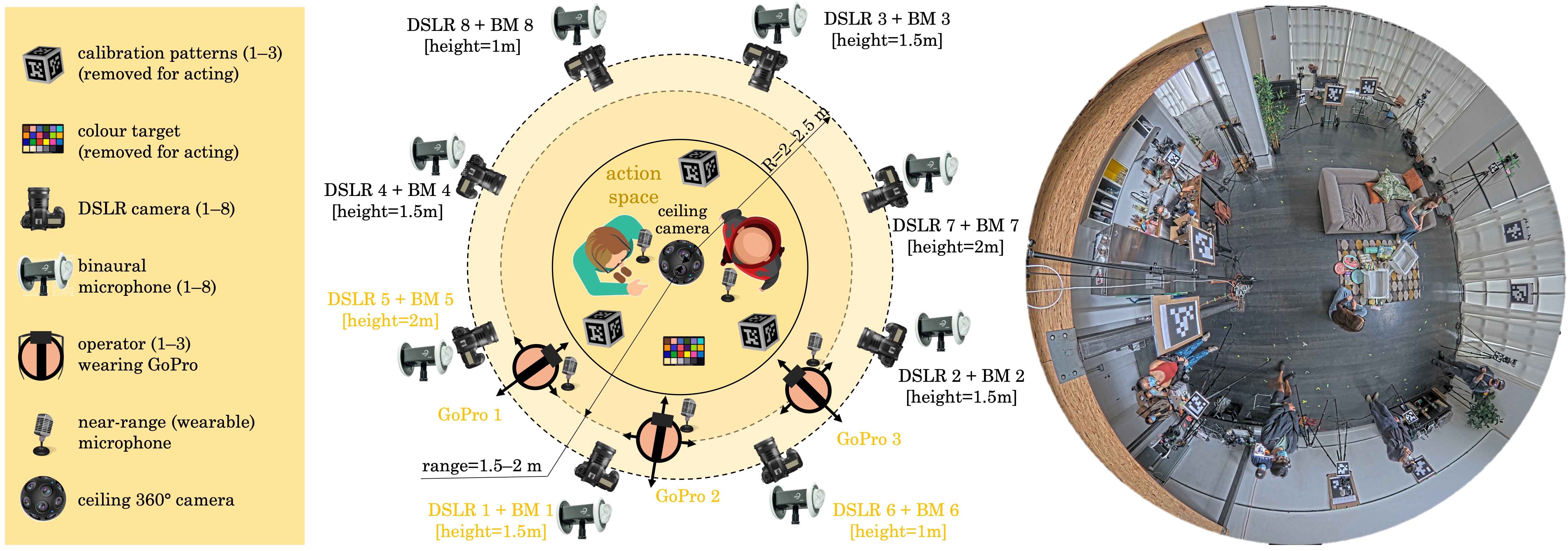
The full Replay dataset consists of 68 scenes of social interactions between people, such as playing boarding games, exercising, or unwrapping presents. Each scene is about 5 minutes long and filmed with 12 cameras, static and dynamic. Audio is captured separately by 12 binaural microphones and additional near-range microphones for each actor and for each egocentric video. All sensors are temporally synchronized, undistorted, geometrically calibrated, and color calibrated.
Example DSLR Videos and Binaural Audios
(wear headphone to hear the spatial sound)
To access the data, follow the instructions in the github repo.
@inproceedings{shapovalov2023replay, title = {Replay: Multi-modal Multi-view Acted Videos for Casual Holography}, author = {Roman Shapovalov and Yanir Kleiman and Ignacio Rocco and David Novotny and Andrea Vedaldi and Changan Chen and Filippos Kokkinos and Ben Graham and Natalia Neverova}, year = {2023}, booktitle = {ICCV}, }@inproceedings{chen2023nvas, title = {Novel-view Acoustic Synthesis}, author = {Changan Chen and Alexander Richard and Roman Shapovalov and Vamsi Krishna Ithapu and Natalia Neverova and Kristen Grauman and Andrea Vedaldi}, year = {2023}, booktitle = {CVPR}, }